How I Designed a Disaster Recovery Architecture That Achieves Sub-40-Minute RPO & RTO in Production
Disaster recovery is a business problem before it's a technical one. The right strategy starts with a single question: what can the business actually afford to lose? With a tolerance of up to one hour of data loss and downtime, a Pilot Light architecture on AWS proved to be the ideal fit — keeping non-compute infrastructure live in a secondary region at all times, while provisioning compute only at failover. Layered data replication, parallel CI/CD pipelines, and fully automated CloudFormation scripts bring the total recovery time to well under 40 minutes — validated through quarterly DR drills. The key insight: over-engineered DR is a hidden cost, and under-tested DR is a hidden risk.
Sadeel Anjum
April 12, 2026

Downtime is not just a technical problem. It is a business problem.
Every minute a production system is down, revenue is lost, trust erodes, and someone in a boardroom is asking why it happened and how fast it can be fixed. As a Cloud Architect, one of my most impactful responsibilities is making sure that question never has to be asked in the first place. Recently, I designed and implemented a full Disaster Recovery (DR) architecture for a production environment on AWS — achieving both RPO (Recovery Point Objective) and RTO (Recovery Time Objective) comfortably under 40 minutes. Here is how I approached it, and what I learned.
The Business Context First

Before touching a single AWS service, I asked the right question: What can the business actually afford?
The answer was clear — up to one hour of data loss and one hour of downtime was acceptable. This immediately ruled out expensive, over-engineered solutions like Active-Active or Warm Standby. The business needed protection, not perfection. That distinction matters enormously when it comes to cost.
The right strategy here was Pilot Light — keep the absolute minimum running in the DR region at all times, and spin everything else up only when needed.\
Why Pilot Light — and Why Not the Others
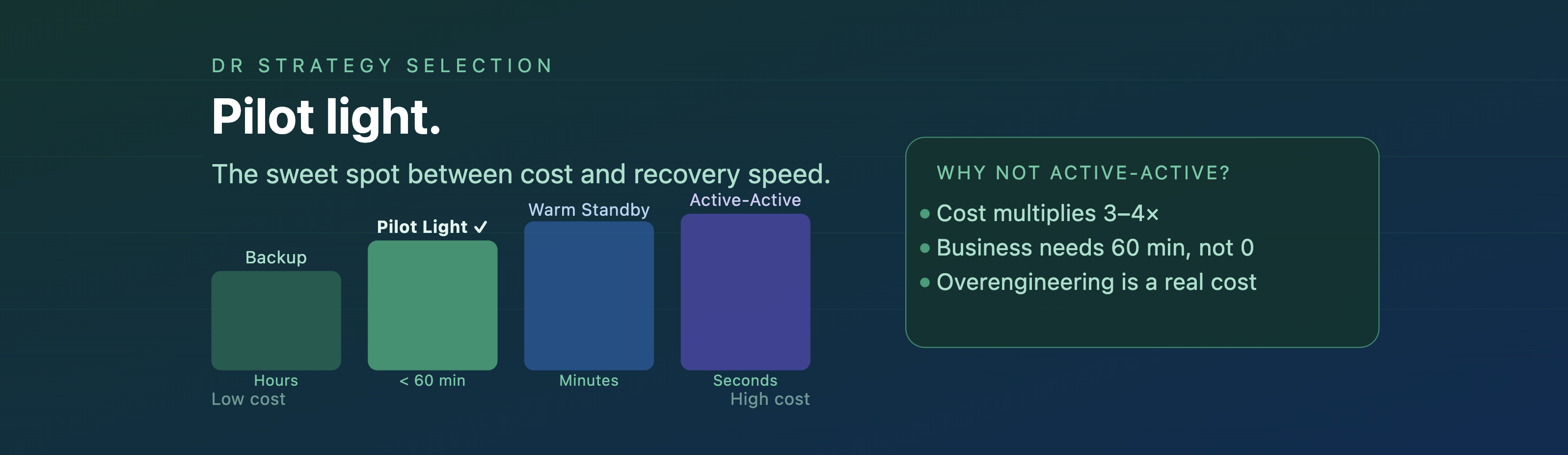
AWS offers four main DR strategies, each with a different cost/recovery tradeoff:
- Backup & Restore — cheapest, but slowest (hours of RTO)Pilot Light — minimal footprint, fast enough for sub-40-minute recovery ✅Warm Standby — faster, but significantly more expensiveActive-Active — near-zero RTO, but cost multiplies dramatically
For our requirements, Pilot Light hit the sweet spot. The non-compute infrastructure stays live in the DR region 24/7. The compute layer is provisioned only at the moment of failover. This keeps the ongoing DR cost minimal while still enabling a fast, structured recovery.
The Architecture: What Lives Where
The application stack included: ECS Fargate (compute), Aurora PostgreSQL (relational data), DocumentDB (document store), DynamoDB (NoSQL), Amazon S3 (object storage), and ECR (container images). Infrastructure was managed entirely with CloudFormation — no Terraform. Since the entire stack runs on AWS, CloudFormation is the natural choice: native integration, no state management overhead, and maximum reliability within the AWS ecosystem.
Both the primary and DR regions were within Europe — driven by where the users are located and by data compliance requirements.
In the primary region: Everything is deployed — compute and non-compute — fully managed via CloudFormation.
In the DR region: Only non-compute resources are pre-provisioned and kept live. No ECS services, no running databases. Just the foundational infrastructure, ready and waiting.
Solving the Hardest Problem: Data

Data is always the most critical tier in any DR plan. Getting the infrastructure right means nothing if the data is stale or missing.
Here is how each data layer is handled:
AWS Backup is configured to back up both SQL (Aurora PostgreSQL) and NoSQL (DocumentDB) databases every single hour, 24/7. That means 24 recovery points per day, per database — with a full month of retention. These backups are automatically replicated to the DR region. At any given moment, we can restore to any point within the last 30 days, at one-hour granularity.
DynamoDB Global Tables handle DynamoDB replication natively — real-time, automatic, with no additional backup configuration needed.
Amazon S3 Cross-Region Replication (CRR) ensures all critical object data is continuously mirrored to the DR region.
The result: data replication running continuously at near-zero marginal cost, with maximum recovery granularity.
Solving the Application Layer: Code and Containers
For the application, I moved away from an on-demand deployment model entirely. Every time a pipeline runs in the primary region, a corresponding pipeline for the DR region triggers automatically — in parallel, at the same time. The same code is built and deployed to the DR environment continuously, not just at the moment of a disaster.
One important nuance: the DR pipeline is not a simple image replication. Since the container images carry region-specific configuration, a direct copy from the primary region would not work correctly in the DR environment. Instead, a dedicated pipeline rebuilds the image independently for the DR region, ensuring the deployed artifact is always environment-correct and ready to run without modification.
To keep ECR storage costs in check, lifecycle policies are applied on the DR ECR repositories — images older than a defined retention threshold are automatically purged. This ensures the registry stays lean regardless of how long the system runs without a disaster event, eliminating unnecessary storage accumulation over months or years.
The result: the application layer in the DR region is always in sync with production, cost-controlled, and environment-ready. When a disaster is declared, the application is already there. The only remaining step is restoring the data tier from the latest available snapshot — the team focuses entirely on data recovery and DNS switchover, nothing else.
The Failover Sequence: Under 20 Minutes to Live

When a disaster is declared, the recovery sequence runs as follows:
- A job is triggered — via Slack command, automated AWS event, or manual initiation.CloudFormation scripts execute — they detect the latest available snapshots in the DR region and provision the databases automatically. No manual snapshot selection. No guesswork.Databases are live within ~20 minutes.In parallel, GitHub Actions pipelines build and deploy the application. By the time the databases are ready, the application is already deployed.DNS is switched via Route 53 — currently a manual step, with full automation in progress using Route 53 health checks and failover routing policies.
Total time: well under 40 minutes. Every DR drill has confirmed this.
Quarterly Drills: Trust the Process, Not Just the Plan

A DR architecture that has never been tested is not a DR architecture — it is a hypothesis.
Every quarter, I simulate a full disaster scenario and run the complete failover process end to end. Every drill has met the RPO and RTO targets comfortably.
These drills also serve another purpose: they surface gaps before a real incident does. As the product evolves — new ECS services, schema changes, new data stores — the DR configuration needs to evolve with it. I treat DR maintenance as a continuous engineering responsibility, not a one-time project.
Key Takeaways for Architects and Engineering Leaders

- Start with the business requirement, not the AWS service. RPO/RTO targets determine your strategy. Over-engineering DR is a real cost that organizations regularly overlook.Pilot Light is underrated. For teams with 30–40 minute tolerance, it delivers serious protection at a fraction of the cost of Warm Standby or Active-Active.Data replication should be continuous and automated. Manual backup processes introduce human error and risk at exactly the wrong moment.Infrastructure as Code is non-negotiable for DR. CloudFormation (or equivalent) ensures your DR environment is always in sync with production. Manual DR environments drift. Code does not.Test it. Quarterly, at minimum. A drill is the only way to know your architecture actually works.
Disaster recovery is not glamorous work. But when something goes wrong at 2 AM, it is the most important work you ever did.
If you are architecting or thinking about your DR posture — I am happy to discuss what the right approach looks like for your system. Feel free to connect or drop a comment below.
#AWS #CloudArchitecture #DisasterRecovery #ECS #CloudFormation #DevOps #Reliability #Infrastructure
Written by Sadeel Anjum
Cloud Architect · AWS Expert